
一、前言
当前,数据流通不畅的问题普遍存在,成为制约数据价值发挥的瓶颈。尽管行政手段推动数据共享发挥了积极的作用,但委办局和各地市的数据家底依然难以摸清,很多有价值的数据并未收集上来。而企业出于经营压力,更难服从行政指令。一方面,业务部门对公共数据的需求不强烈,另一方面,数据局对业务应用的理解也存在客观的局限性,使得数据流通效果不佳。此外,数据治理、数据运营、数据服务的人力成本居高不下,加之对数据安全隐患的顾虑,进一步加剧影响了数据流通的时效性。
我们看到某地一个自认为非常成功的数据局,他们斥资建设的大数据系统,结果总共才调用了数据局的数据1000余次。相比之下,上海某数据局累计调用了高达12亿次数据,涉及70亿条不重复的数据。数据流通的活跃度是衡量建设效果的重要指标。
为了解决上述问题,我们需要从方法论上进行深入思考。排除行政因素外,通过自动化源数据编目与归集、以及自动化生成服务接口和微服务部署,是解决数据收集与共享流通难题的技术关键。通过自动化手段,主动适配业务源端情况,我们可以减少对源端人员的打扰,提高数据收集的广泛性和及时性,确保业务需求部门能够及时拿到新鲜的数据。
进一步地,我们需要深入分析业务部门需求不强烈的原因。是否是因为数据更新不及时、不适用,服务接口定制太慢,或者数据查询申请不方便?由于考核的存在,业务部门更希望能简单地找到需要的数据,而不希望频繁地向数据局提问。因而,数据局可以尝试结合AI大模型方式,理解业务部门的对话需求,通过样例数据计算结果,告诉业务部门需要申请哪些表哪些接口。这样能提高业务需求部门申请数据的积极性。
从安全合规上讲,我们可以将敏感字段标注和注释交由源端完成,结合后端数据自动探查方式,实现数据的权限管理、分类分级和动态脱敏。这样既能保障数据的安全,又能提升数据服务的便捷性和灵活性。
自动化手段可以大大降低数据局运营人员的基础数据处理的工作量。所以,推动自动化编目归集与共享服务系统的建设和发展,是价值数据流转的有力支撑。
二、功能介绍
(一)自动化源数据编目
当前很多源数据目录的收集,主要采用EXCEL或表格申报方式,这会增加委办局业务部门巨大工作量,因而在挑选申报过程中,极可能遗漏掉很多有价值的信息项。而且,随着业务部门系统升级和变化,他们申报的EXCEL或表格,也会与真实系统出现诸多偏差。
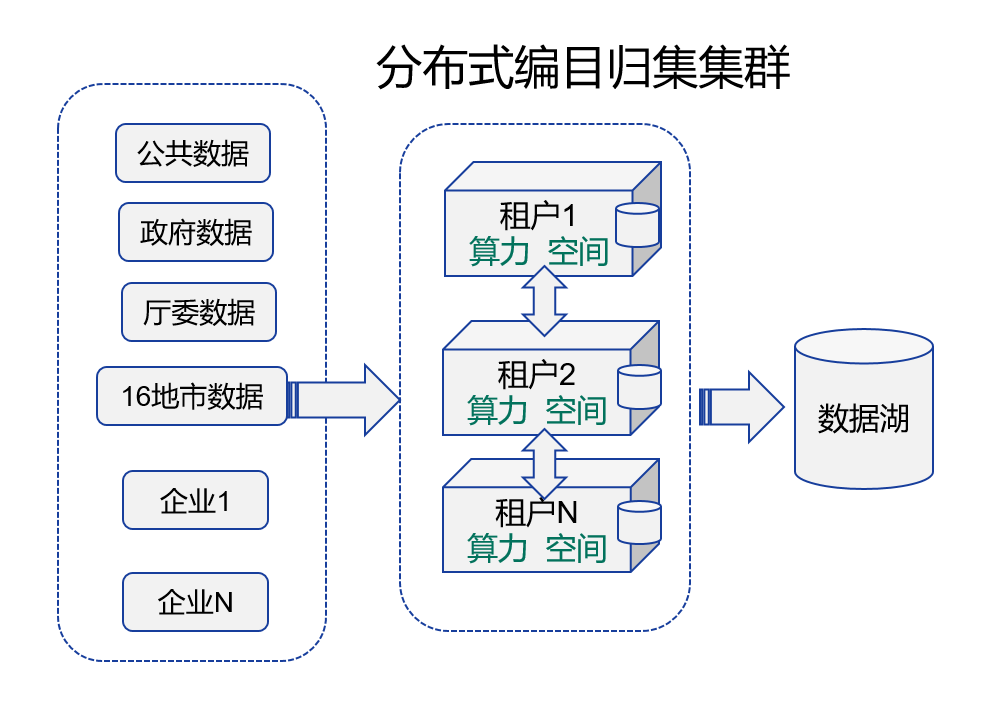
因而我们采用源数据目录自动编制的方式,按租户为每个业务部门分配一套逻辑独立的编目归集系统。业务部门在登记了应用系统最基本信息,以及填写了最基本的数据库只读账号后(前后大约15分钟时间),编目归集系统会自动采集数据库所有表的元数据信息,包括表、字段和注释。这样业务部门和数据局都可以全面掌握应用系统的数据目录底数。业务部门可以填写法律依据保留“不予共享”的数据目录,而将“无条件共享”、“有条件共享”的目录进行发布。发布就意味着目录是可以共享给其他业务单位的。数据局可以从所有信息中筛选有价值的表,进行归集或者敦促业务部门自行归集上传到ODS中。
(二)自动化数据归集
尽管源数据的归集工作可以由数据局数据集成队伍完成,但我们系统支持并建议该项工作由各业务部门自行完成。因为业务部门发布了数据目录,接着系统就引导他们完成库表数据归集工作。这样做的好处是,充分尊重了业务部门的知晓权,也便于他们查看数据归集的对账状态。采用库表同步归集是直接读取业务系统数据,业务部门可以按照全库归集,也可以选择很多张表同时归集。归集的步骤“傻瓜化”,三次“下一步”就提交完成。大批量数据的并行计算和任务排队,交给系统来处理。系统会自动核对源数据编目与数据归集的对应关系,如果数据编目完成了而归集未完成,或者归集了数据却没有编目,系统会提醒这些状态。那么,数据局也可以督导业务部门进一步完善工作。为了鼓励增量归集提高数据及时性以及通过差异检测发现变更的历史数据,在归集向导过程中,系统会提示并推荐增量字段以及差异更新字段。库表归集的性能非常快,单个节点可以达到10万条数据每秒,而作为分布式数据归集系统,能并行归集的性能与节点数成倍数增加。
这样做的好处:
1)降低协调成本。业务部门自行完成归集工作,减少了数据局直接介入的技术对接和沟通成本,将数据局角色从执行者转变为监督者,更聚焦于全局统筹和规则制定。
2) 简化操作与资源释放。无需依赖专业技术团队,普通业务人员即可完成。
3) 安全与合规。归集过程由业务部门直接控制,可自主设定数据开放范围和权限,降低数据泄露风险。
当然,对某些执行不力,或者数据及时性要求很高的数据,数据局可以进入系统调整配置完成数据归集任务。
然而,某些业务部门仅仅提供了API接口,甚至含有加密数据的接口。我们依然可以适应这些复杂的场景。

系统通过配置引导自动生成接口,包括接口归集的任务策略,可以适应几十种复杂场景的接口对接,实现自动数据归集。
(三)自动化API接口生成及共享服务
数据局已经部署了接口网关(如:Spring Cloud Gateway),但是一个接口服务的生成链路比较长,依然需要人工参与到如下工作中:
1)接口定制开发。包括业务逻辑实现、数据库交互、状态处理等。
2)网关代理与安全设置。在接口服务完成后,通过网关代理来对接口进行流量管理、安全增强、监控等功能。
3)查询服务实现。针对查询类接口服务,优化数据查询效率和响应速度,同时处理复杂查询业务逻辑。
4)接口测试与优化。测试接口服务的功能是否符合设计规范,性能是否优化。
5)部署和上线。将开发完成的接口服务部署到生产环境,通过集成工具或手动调整完成上线。
通常一个接口从开发、测试到部署,需要1-2天时间。遇到复杂的有关动态鉴权以及数据加密相关的接口开发,往往需要1周以上的时间,对人员技术要求也不低。程序员还要考虑缓存、分页、认证、防SQL注入等性能与安全问题,以及撰写接口文档。
通过我们自动化API接口生成及共享服务,我们将如上过程封装到系统中自动实现,让运营人员只关注业务逻辑的选择配置,从原来的1-2天时间,缩短到5分钟上线,自动生成接口文档。
我们采用IP白名单、身份鉴权、动态签名(appKey、AppSecret、时间戳timeStamp、签名sign)、防SQL注入、支持HTTPS等方式维护API接口服务的安全。
系统支持代理接口和库表接口的自动生成与微服务部署上线。
代理接口是指代理第三方提供的接口,比如代理国家行政服务中心发布的接口。这是因为国家行政服务中心通常为每个省发放的用户账号有限,因而每个经办局业务单位可以通过省数据局的代理接口获取国家行政服务中心的数据。 库表接口的生成与自动化部署支持三种方式:单表生成接口、SQL联合查询生成接口、JAVA和JAR包生成接口。每种接口都可以在线测试、进行上下线管理并查看接口文档。
1、 单表生成接口服务。只需要按照向导,选择入参和出参就自动生成接口了。
2、 SQL联合查询生成接口服务。动态查询/聚合统计。
例如:
用户要实现查询订单信息时需关联订单表(order)、订单项表(order_item)、用户表(user),我们只需要在本系统的SQL输入框中将查询字段,用 #{} 表示为变量,就可以了。
WHERE
o.created_time BETWEEN #{startTime} AND #{endTime} -- 创建时间范围
AND (o.order_no = #{orderNo} OR #{orderNo} IS NULL) -- 订单号(若未传入则忽略)
AND (o.user_id = #{userId} OR #{userId} IS NULL) -- 用户 ID(若未传入则忽略)
ORDER BY
o.created_time DESC; -- 按订单创建时间降序排列
而业务部门的接口调用,还需要填写具体数据就可以自动对接。
如:
{
"startTime": "2023-01-01",
"endTime": "2023-01-31",
"orderNo": null,
"userId": null
}
3、JAVA和JAR包生成接口服务
-
需动态加密敏感数据或实现复杂业务逻辑。
-
要求细粒度权限控制。
-
其他单表接口或者SQL接口处理不了的场景。
总结:通过可视化配置生成服务接口,可以在10分钟内完成从接口生成到自动部署上线,且生成代码可直接融入微服务治理体系(如监控、链路追踪)。此外,系统提供了接口日志监控,自动统计接口使用数量、各机构调用接口情况、每个接口被调用情况以及接口请求异常及响应时间等日志列表。