
当我们提到“你的BI为什么运行得很慢?”时,很多人可能会想,问题就出在BI系统本身,或者是硬件配置不够好,但其实,根本的原因往往在于数据架构设计不合理,特别是没有合理的数据分层。
什么是数据分层?
在数据管理中,数据分层是一种将数据按照不同的处理和使用需求,分为多个层级来管理的方式。常见的分层包括:
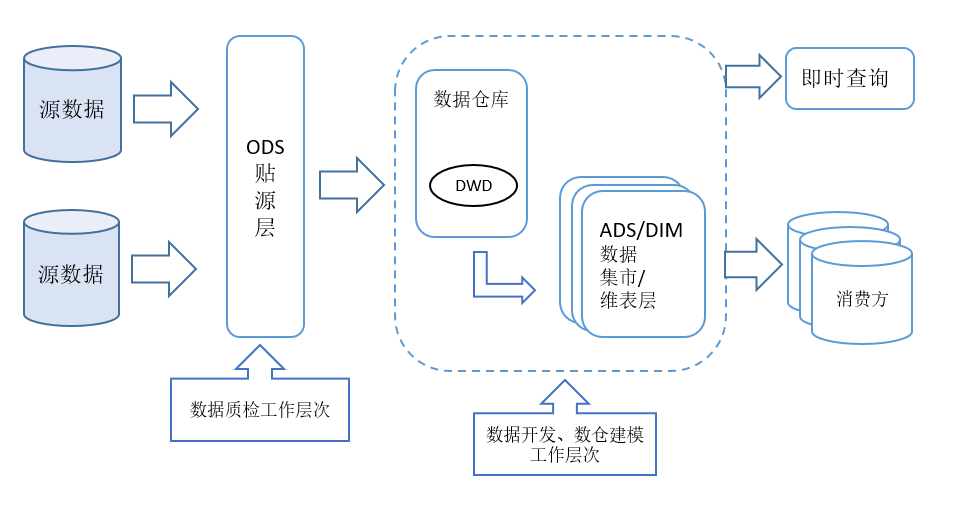
ODS(操作数据存储层):原始数据,基本没有做处理,来自各个业务系统。
DWD(数据仓库明细层):经过清洗、去重和初步加工的数据,用来提供详细的数据支持。
ADS(分析数据层):经过聚合、优化的数据,专门用于BI报表和分析,查询非常高效。
如果没有数据分层,所有的数据处理都会集中在一个地方,BI系统每次查询时都要重新做很多计算,这就导致了查询变慢,系统卡顿,特别是在数据量大的时候,性能问题会更明显。
为什么没有数据分层,BI会很慢?
1)原始数据过多,计算太复杂
没有数据分层,BI系统往往直接从ODS层(原始数据)甚至直接从源业务系统数据库中获取数据。这些原始数据没有经过任何清洗、汇总或优化,可能包含了大量不相关的数据。如果每次报表查询都需要从数百万条数据中筛选并进行复杂计算,响应时间必然会很长。没有数据分层,你的查询需要在每次访问时都去做大量的冗余工作,系统自然会变慢。如果直接从源端业务系统获取数据,由于每次要从大量业务数据中筛选数据,这些计算肯定会影响源端业务系统的性能。
2)数据冗余和重复计算
假设你的数据集包含很多重复信息,比如每条记录都有时间戳、用户ID等相同的字段。每次分析时,系统都会重新计算这些冗余的数据,浪费大量计算资源。如果数据没有经过分层清洗,每次查询都会涉及到重复的计算和处理,这显著影响了查询效率和系统响应速度。
3)没有针对性的优化
BI报表通常需要的是汇总数据(比如月度销售总额、客户数量等),而不是每条单独的交易记录。如果直接使用ODS层的数据甚至源端业务系统数据库,那么每次查询都需要去查找所有的细节数据,这样查询复杂且效率低。但是,如果数据经过分层处理,进入DWD层后就已经做了清洗和去重,进入ADS层后还可以进行聚合和优化,BI查询时直接读取这些处理过的高效数据,就能大大提高查询速度。
数据分层如何解决这些问题?
1)ODS层:减少不必要的数据处理
在ODS层,我们保留的是最原始的数据,虽然这些数据很大、很杂乱,但它们是所有数据处理的基础。数据中心通过抽取并存储原始数据,保证了所有数据都有备份。如果直接在ODS层做复杂计算,系统负荷过大。所以,ODS层主要用于存储原始数据,而不用于高效分析。当然,我们也建议,数据质量检查可以在ODS层实现,并产生数据质量报告。
2)DWD层:清洗和优化数据
在DWD层,我们对ODS层的数据进行清洗、去重、标准化转换等处理,使数据变得更规范、更加适合后续的分析工作。通过在这个阶段将无关数据剔除,我们减少了BI查询时需要扫描的数据量,确保了查询更高效。
3)ADS层:专门优化分析数据
在ADS层,我们对数据进行了进一步的聚合和优化,专门为BI报表和分析需求做准备。准备的工作,按照数仓建模理论体系,如“星型模型“”雪花模型”,建立维度表和实时表、子表的关联。例如,销售数据可能会按照时间、地区、产品等维度进行汇总,并且提前计算好常用的统计指标。这样,BI系统只需要读取这些预处理好的数据,就能快速生成报表,而无需再进行大量的计算。
4)数仓模型
数据仓库之父Bill Inmon在1991年出版的"Building the Data Warehouse"一书中所提出的定义被广泛接受
数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策(Decision Making Support)。
经典的数仓模型包括:
“星型模型”:实时表位于中心,维度表直接关联实时表,结构简单查询效率高,适合多维度数据分析。
“雪花模型”:将维度表进一步规范化位多个子表,减少数据冗余,但也可能增加查询复杂度。
“星座模型”: 多个星型模型的组合,适用于复杂业务场景,支持多实时表共享维度表。
过去,由于硬件和数据库性能的限制,必须精细地管理数据冗余、优化查询效率、控制数据量。然而,现代大数据处理技术(如分布式数据库、云计算、列式存储等)提供了强大的计算能力和存储空间,能够处理更复杂、更大规模的数据。如今,我们可以在一定程度上简化模型设计,减少对于极端性能优化的依赖。 随着技术的发展,某些情况下确实可以采用更加简化的模型。
维度表:可以只关注稳定不变的字段,即那些在业务流程中变化较少的维度(如时间、地区、产品等)。只要这些维度能与事实表(即数据分析的核心表)关联,简化模型会提高开发和维护效率。
事实表:对于实时数据的处理,可以根据业务活动的需求来限定表的大小,例如通过分区、时间窗口等方式来管理实时表的数据。这种方式可以减少计算和存储的压力,同时避免过于复杂的数据处理过程。
随着实时数据分析的需求增加,传统的以ETL批处理为主的数仓架构可能不再完全适应现代业务的需求。对于需要实时更新的场景,实时表的设计可能会简化模型,但仍需要保证与历史数据的结合和一致性。传统的离线数据仓库仍然在大数据处理、历史数据分析中扮演重要角色。
5)为什么数据分层能让BI更快?
通过数据分层,数据不再杂乱无章,BI系统不再每次都从头计算所有数据,数据处理的工作被分配到了不同的层级。具体来说:
ODS层:只存储原始数据,不做复杂计算,可以用于数据质量检查;
DWD层:对数据进行清洗和处理,去除冗余信息,让数据更干净,查询时可以直接使用;
ADS层:专门为分析优化的数据层,数据已被聚合、优化,直接查询高效,提升BI性能。
因此,如果你的BI系统运行很慢,首先检查是否有合理的数据分层。通过数据分层,能够极大地提升系统的查询速度和处理效率,减少冗余计算,保证在数据量庞大的情况下依然能快速响应。
结语:
“你的BI为什么运行得很慢?” 这个问题,往往归结于数据架构没有设计好。数据分层的引入,能够有效优化数据的处理流程,减少无效的计算,显著提升BI系统的响应速度。做好数据分层,就是让你的数据更加高效、更加有序,从而让BI系统更加顺畅地为业务决策提供支持。
本文讲解视频请参见:
手机端请关注公众号:数据集成服务
加入讨论群:
