
一. 数据归集习以为常的几大问题
数据归集是大家项目中都会去做的,而且很多朋友也了解很多开源工具。那么你是不是会遇到如下问题呢?
(1)面对几万张表,你是不是只能一张一张地归集? 可能你有全库同步的手段,但是你能不能从一个库5000张表里选择4000张表同时归集呢?
(2)假设一张表10亿条数据,你能让这10亿条数据自动平均分配到5个节点上运行,并且每个节点是按多线程运行,以提升性能吗?
(3)如果你采用的工具不兼容源端数据库版本,你怎么办?
(4)归集前,你是不是需要在目标端先建好表才行?(create table …),几万张表,你要建几万次哦。
(5)源端的数据是按照某个时间戳字段递增的,于是你采用了增量同步方式,以减少时延,但是,源端的另一个字段数据也会发生更新,这种情况下,你是不是只能采用全量同步来解决?而这张表又很大,所以,你也只能眼睁睁地看着,时延很大比如需要8小时全量同步才完成,但你也没办法解决。
(6)如果源端只提供了API让你对接,而且源端的数据是加密的,你需要不需要人工写程序来适配源端的API?
如果以上问题存在,那就说明,项目上需要一只团队来做数据集成工作,运维成本高,而且,数据更新时效性可能不好。
二. 我们的数据归集方式
目前,我们支持的数据归集方式,主要包含如下几种:
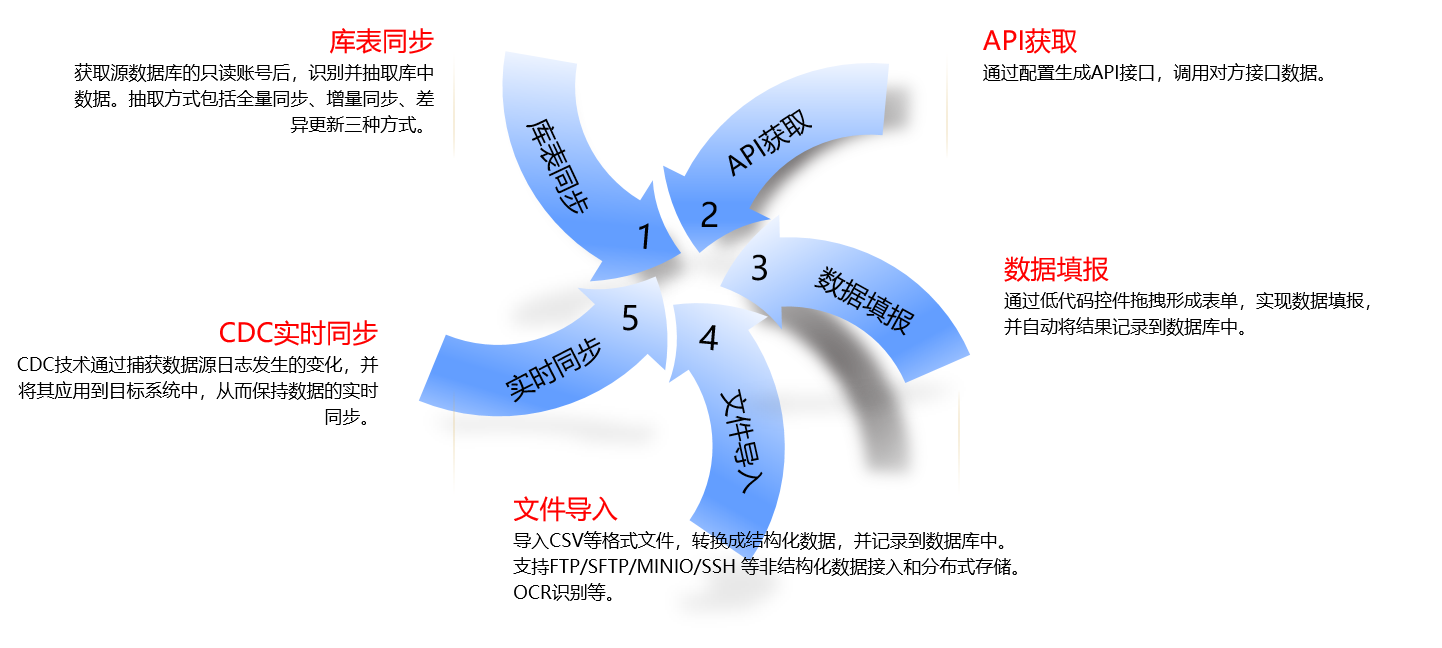
一)库表归集
库表归集通过引导式自动化配置,实现几千张表同时归集的极简配置。底层调用分布式并行计算引擎,所以归集速度快;由于不仅仅是全量同步,还支持增量同步、差异更新同步,所以归集频率和时延都可以降到秒级;通过 JDBC 驱动实现数据库间的方言转换、协议适配与数据类型映射,确保不同数据库间的无缝数据同步,因而能对广泛的数据兼容性更强。汇聚不同来源数据,建立自动适配异构数据源自动化同步方法,实现包括关系型数据库MySQL、Oracle、DM、GuassDB等、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
• 采集速度快,采用分布式多节点部署, 单节点采集速度最高达到10万条/秒。支持断点续传。支持限制传输速率。
• 支持多种数据来源,除了各种关系数据库、NOSQL 数据库。
• 不影响源端系统对源端无干涉的情况下,稳定数据传输,可以限制传输速率。
• 不在数据源安装插件,对源端无干涉。支持全量同步、增量同步、差异更新同步。支持单表、多表、全库、多库的数据自动归集。
• 引导式归集策略定义,简单方便。详尽的任务记录全留痕、统计报表和异常提醒追溯,在线查看日志。

增量同步与差异更新同步
增量同步是指只从数据源中抽取新增的数据,并将其插入到目标系统或数据仓库中。其原理如下:
• 数据变化识别:通过比较源端库表和目标系统或数据仓库中对应字段的时间戳、序列号或唯一标识等信息,识别出新增的数据记录。
• 数据读取:从源端库表中读取识别出的新增数据记录。
• 数据传输与插入:将读取到的新增数据传输到目标系统或数据仓库中,并插入到相应的表中。
• 增量同步的优点是能够减少数据抽取的时间和资源消耗,提高数据抽取的效率。归集系统需要维护额外的元数据(如时间戳、序列号等)来跟踪数据的变化。该方案需要有“动态跟踪增量插入算法”:
(1)首次任务,首先开始读取源端全量数据。
(2)第二次任务,第一次读取增量数据。此时,源端在最后1毫秒期间产生了1000条数据,读取的一刹那,归集系统只获取了最后1毫秒的1000条数据中的前600条数据
(3)第三次任务,第二次读取增量数据,必须要能知道上1毫秒,还有400条数据需求读取,然后再从下一毫秒开始读取增量数据。
该算法的两个核心特点:
• 动态跟踪:算法能够动态地识别并跟踪数据源中新增的数据记录,通过时间戳、序列号或唯一标识等信息来定位新增数据。
• 增量插入:明确了算法的操作方式,即将识别出的新增数据插入到目标系统或数据仓库中,而不是进行全量数据抽取,从而提高了数据抽取的效率。
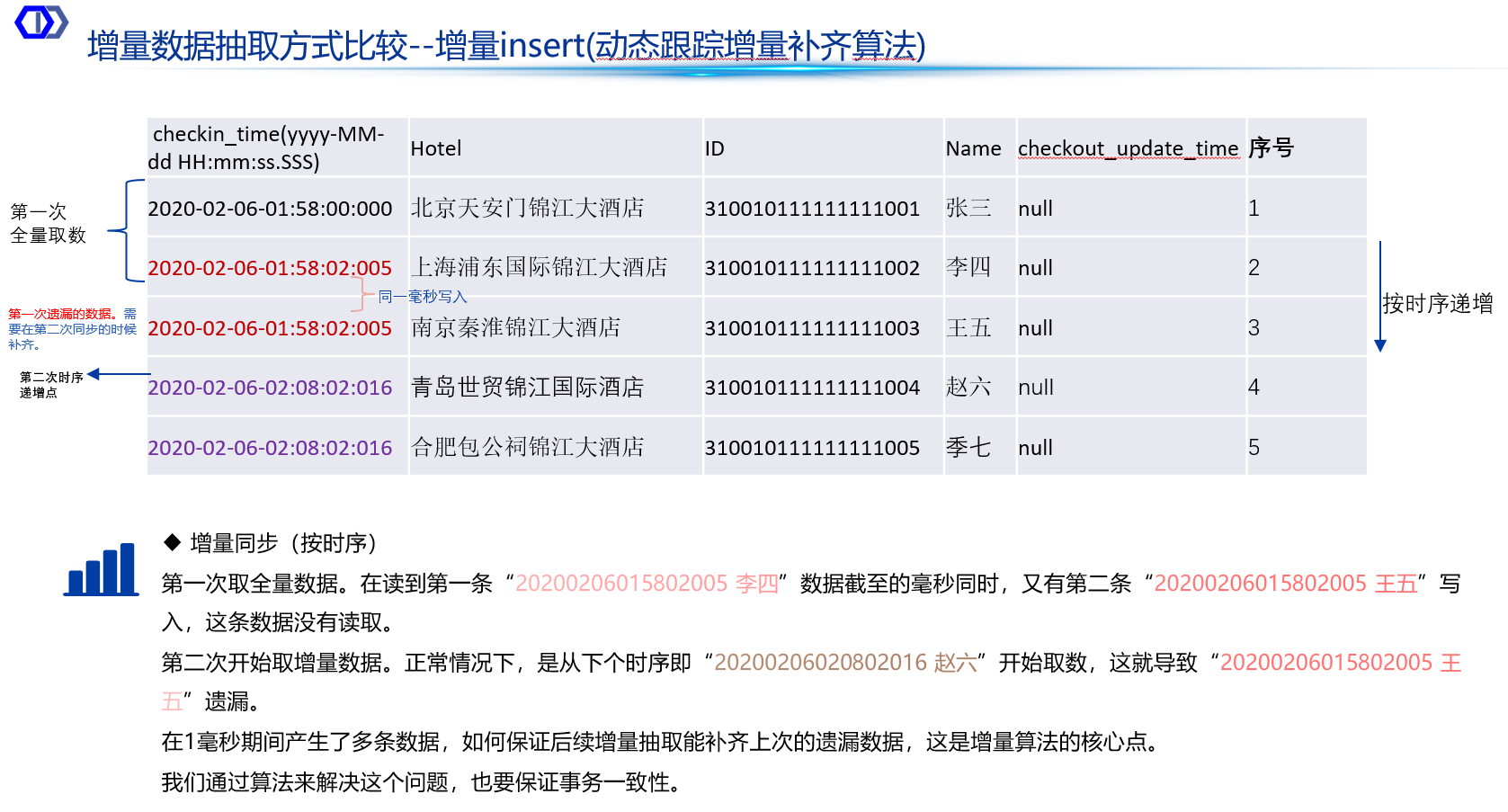
图-动态跟踪增量插入算法
• 差异更新同步是指基于增量同步的机制基础上,能发现从数据源中已经抽取过但是却发生变化的数据(包括修改和删除),将过去已经抽取了但发生变化的数据,重新更新到目标系统或数据仓库中。其原理相对复杂,具体步骤如下:
• 数据变化识别:同样通过比较源端库表和目标系统或数据仓库中对应字段的时间戳、序列号或唯一标识等信息,识别出已经抽取过但已发生变化的数据记录。对于修改的数据,需要确定哪些字段发生了变化;对于删除的数据,需要确定哪些记录被删除。
数据传输与更新:
• 对于修改的数据,将读取到的变化数据传输到目标系统或数据仓库中,并更新到相应的表中。更新操作通常包括定位到需要更新的记录,然后替换或修改相应的字段值。
• 对于删除的数据,需要在目标系统或数据仓库中执行删除操作,以删除相应的记录。删除操作通常通过匹配唯一标识或主键来实现。
• 差异增量更新的优点是能够确保目标系统或数据仓库中的数据与源端库表中的数据保持一致。归集系统需要采用复杂的逻辑来识别和处理数据的变化,同时利用并行读写引擎快速执行读取和更新操作。
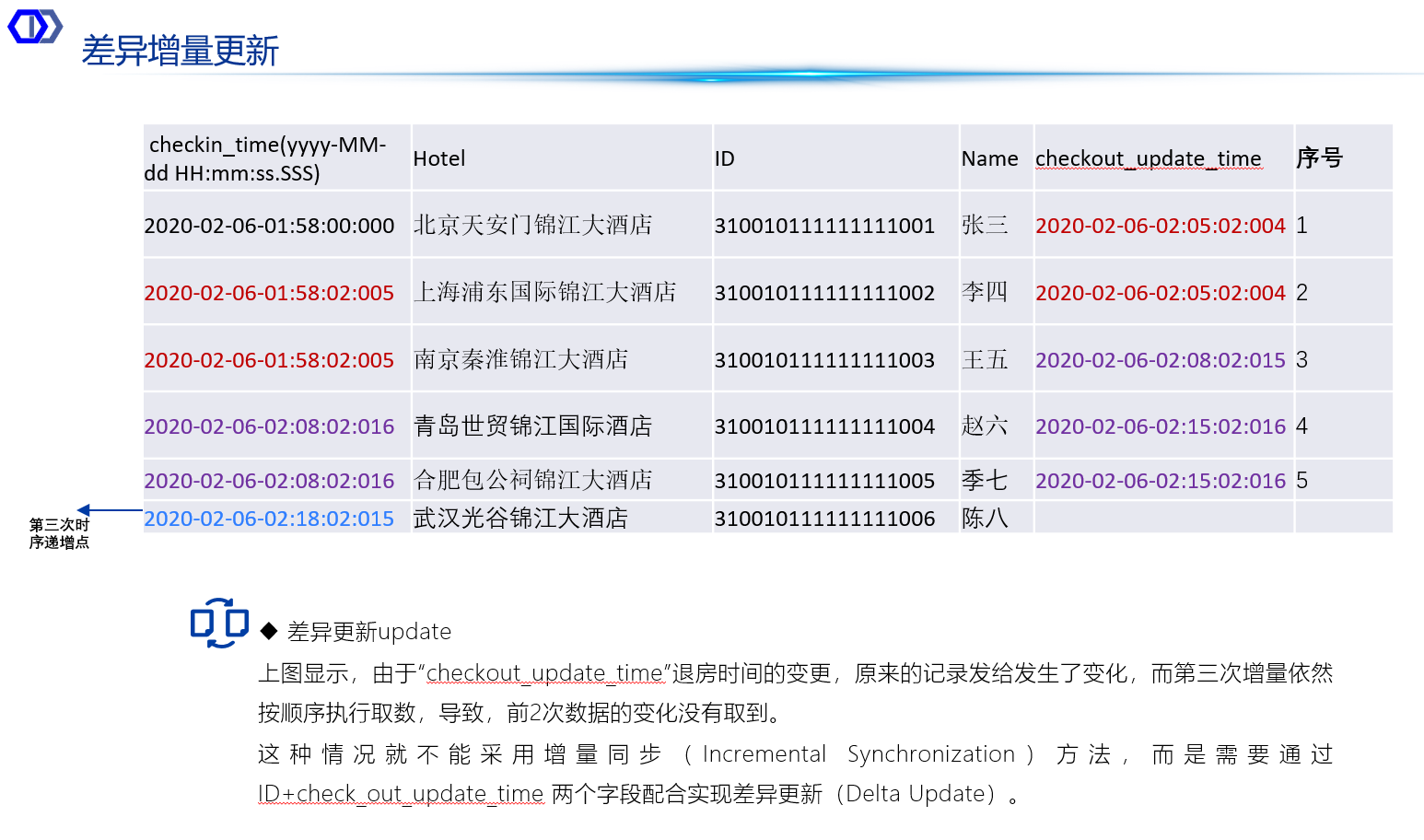
图-差异增量更新要管理数据变化的字段
二)接口归集
接口归集是一个通过界面配置自动生成接口归集并从源端获取数据的工具。它支持 GET、POST、PATCH 等 HTTP 请求方法,允许用户配置 URL 参数、Body 参数、请求头,并提供参数转换功能(无需转换和采用Java脚本转换)。该工具支持多种 BODY 参数格式(form-data、application/json、text/plain),并且参数来源可以是自定义或来自库表配置。
1、API接口归集过程
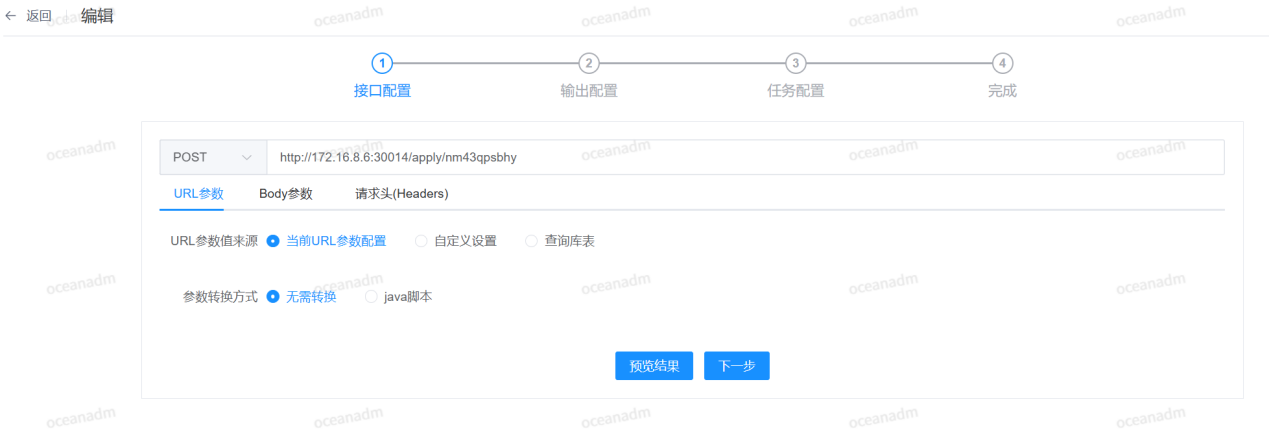
(1)界面配置
• 用户通过图形化界面输入 API 的基本信息,包括请求方法(GET、POST、PATCH 等)、URL、URL 参数、Body 参数、请求头等。
• 用户可以配置 URL 参数,这些参数可以是静态值,也可以是来自其他库表或自定义变量。
• Body 参数支持 form-data、x-www-form-urlencoded、application/json、text/plain 等格式,用户可以选择参数来源(自定义或库表配置)。
• 请求头支持自定义设置,并允许使用 Java 脚本对请求头进行任意转换。
• 可以在Body中提交任意复杂的长SQL,轻松实现多表JOIN、子查询等,精确获取任何想要的数据组合和计算结果,这是URL无法做到的。
(2)参数转换
• 无需转换:直接使用用户配置的值。
• Java 脚本转换:用户可以编写 Java 脚本对参数进行转换,以满足源端接口的特殊要求。
(3)API 生成与调用
• 根据用户配置的信息,系统动态生成对应的 API 请求代码。
• 系统调用生成的 API 请求,通过客户端向源端发送请求。
• 系统接收源端返回的响应数据,并进行必要的处理(如解析 JSON、处理异常等)。
(4)结果展示与存储
用户可以选择将响应数据存储到指定的库表中,以便后续分析和使用。
2、API接口对接的特点
系统提供了一个高度灵活、配置驱动、可编程扩展的轻量级数据集成与API自动化平台,“接口归集”工具,其本质是一个以元数据驱动、具备动态脚本能力的轻量级API-ETL(提取、转换、加载)工具。它的核心价值在于,让不具备编程能力的人员也能通过图形化界面,完成复杂API的数据拉取、处理和入库工作。
我们这个软件模块不仅是一个API调用工具,它是一个集数据源连接、数据转换、动态鉴权、批量执行、可编程逻辑于一体的数据集成中间件。它在“声明式配置”的易用性和“编程式扩展”的灵活性之间取得了平衡,使其能够高效、可靠地解决从简单到极其复杂的各种API对接和数据同步场景。
软件模块技术特点
1)高度灵活的请求配置能力 (Highly Flexible Request Configuration)
可以轻松适配市面上几乎所有主流的HTTP API请求方式。
• 全面覆盖:从最简单的GET请求,到复杂的POST请求,无论是URL参数、Body参数还是Headers,都能自由配置。
• 支持多种Body类型:支持form-data、x-www-form-urlencoded、application/json、text/plan等常见内容类型。
• 静态与动态结合:参数可以写静态值,也可以是动态生成的变量。
一句话总结:只要是标准的HTTP(S)接口,这个模块就能对接。
2)声明式的批量数据处理引擎 (Declarative Batch Data Processing Engine)
具备“ETL工具”的核心价值体现。
• 数据驱动循环:可以通过一句SQL或者一个自定义JSON数组来提供一个数据列表。从而一次性批量地入参返回结果。
• 自动迭代:模块会自动遍历列表中的每一条数据,并为每一条数据发起一次API调用。
• 模板化替换:在每次调用时,自动将列表中的数据(如{eventId})填充到API的URL、Body或Headers的模板中。
一句话总结:实现了“一次配置,批量执行”,将数据处理从手动变为自动。
3)强大的内置数据转换能力 (Powerful Built-in Data Transformation)
在将数据发送给API之前,模块提供了多种“开箱即用”的数据处理方式。
• 源端转换 (In-Source Transformation):允许在数据源(如数据库)层面就完成复杂的格式化和计算。比如针对DATE_FORMAT 进行 concat,这极大提升了效率。
• 结果处理:“返回结果解密”,这说明模块不仅能“发”,还能对返回的数据进行预处理,为后续的数据入库或二次加工做好准备。
一句话总结:在数据到达API之前,就能将其“精加工”成所需的样子。
4)复杂的认证与动态鉴权处理 (Complex Authentication & Dynamic Authorization)
模块能应对各种复杂的API身份验证机制,这在企业级对接中至关重要。
• 静态认证:支持在Headers中配置固定的accessKey和accessPwd,这是最基础的鉴权方式。
• 动态Token获取(编程式):通过强大的Java脚本能力,它可以:
⚬ 执行多步HTTP请求(先获取code,再用code换token)。
⚬ 进行复杂的加密签名运算(如MD5)。
⚬ 动态构建时间戳、拼接字符串等。
⚬ 最终将计算出的accessToken动态填入到主请求的Headers中。
一句话总结:无论是简单的Key/Secret,还是复杂的动态Token握手协议,都能搞定。
5) 极致的可编程扩展性 (Ultimate Programmable Extensibility)
当标准配置无法满足极端复杂的场景时,模块提供了“最后一道杀手锏”——Java脚本。
• 全流程干预:Java脚本几乎可以干预请求的任何部分(尤其是Headers和Body的构建),甚至可以在主请求发起前,先执行任意复杂的逻辑和外部API调用。
• 利用成熟生态:脚本中可以使用如Hutool这样的第三方库,极大地扩展了功能边界,无论是加密解密、JSON处理还是HTTP请求,都信手拈来。
• 逻辑兜底:它为所有声明式配置无法解决的“疑难杂症”提供了最终解决方案。
一句话总结:既有低代码的便捷,又有纯代码的灵活与强大。
6) 极简配置与零配置能力 (Minimal & Zero-Configuration Capability)
在强大和复杂之外,模块同样追求简单。
• 开箱即用:对于简单的API,用户几乎不需要任何复杂的配置,只需填入URL即可。
• 配置即文档:模块的配置界面本身就清晰地定义了API的调用方式,直观易懂。
一句话总结:简单场景足够简单,复杂场景也游刃有余。
7) 动态参数聚合与预处理引擎 (Dynamic Parameter Aggregation & Pre-processing Engine)
在发起API请求前的“准备工作”需要智能和自动化。
• 多元化数据源融合:它不仅仅是从一个地方获取参数,而是能够将来自**静态配置(自定义)和动态数据库(库表配置)**的“配置”融合在一起。
• 请求前置渲染:在真正发起请求的瞬间之前,引擎会进入一个**预处理(Pre-processing)**阶段。它会智能解析配置,先去数据库查询所需数据,然后像“填词游戏”一样,将这些动态数据精准地填充到请求的URL、Header或Body的模板中。
• 内置模板引擎:这个能力说明,模块内部集成了一个轻量级的模板渲染引擎,专门负责将数据和模板无缝结合,生成最终的请求报文。
一句话总结:能在请求发出前,动态“组装”和“渲染”参数的智能引擎。
8) 安全可靠的脚本执行沙箱 (Secure & Reliable Scripting Sandbox)
在追求灵活性的同时,对安全性的不能妥协。
• 隔离的运行环境:用户提交的Java脚本并不会在操作系统的“开放世界”里运行,而是被关在一个**“安全沙箱”**里。这个沙箱严格限制了脚本的“权力”,禁止它触碰文件系统、随意访问网络或执行其他高危操作。
• 性能优化意识:为了避免每次运行脚本都重新编译导致的性能瓶颈,平台具备编译缓存的意识。对于固定或频繁使用的脚本,可以缓存起来,下次直接调用,大大提升了执行效率。
一句话总结:它给了用户“代码级”的自由,但又做了安全限定,确保了系统的稳定和安全。
9) 精密的任务编排与调度核心 (Sophisticated Task Orchestration & Scheduling Core)
这展示了模块不仅仅是执行单个动作,而是在后台指挥一个完整的“自动化生产线”。
流程化工作流引擎:模块内部有一个任务编排引擎,格按照预设的工作流来调度每个环节:严格按照
配置解析 -> 数据库取数 -> 脚本转换 -> API调用 -> 解析返回结果 -> 数据入库 的顺序执行。
一句话总结:它不仅是一个工具,更是一个拥有内置工作流引擎的“自动化调度中心”。
10)企业级的健壮性与容错机制 (Enterprise-Grade Robustness & Fault Tolerance)
这体现了模块在面对现实世界中各种意外情况时的“抗打击能力”和“自我修复能力”。
• 全链路异常监控:平台对任务执行错误环节,如数据库连不上、脚本代码出错、API网络超时,还是返回的数据格式不对,都能被即时捕获。
• 智能重试策略:当遇到网络波动或对方服务器临时故障这类“可恢复”的错误时,用户可以配置重试策略(例如“3秒后重试,最多重试5次”),让模块自动尝试,极大地提高了任务的成功率。
• 完善的错误处理:完善的记录和报告机制,让用户能快速定位问题所在。
三)文件归集
系统支持通过文件导入的方式获取数据,并自动导入到关系型数据库和非关系型数据库如Hive中。提供多种格式的数据文件导入,包括但不限于csv、txt、xlsx、lsx ,并将支持json,xml,orc文件上传资源。
四)非结构化文件获取与存储
我们通过支持FTP、SFTP、SSH等多种文件传输方式,将各地各系统产生的非结构化文件(如图片、音视频、文档等)自动归集到统一平台。归集后的文件会存入Minio分布式文件存储系统,实现文件的高效分布式存储和集中管理。这保证了非结构化数据的安全性、可靠性和可扩展性,同时便于后续的统一访问和管理。
五)实时同步
CDC实时同步,即Change Data Capture(数据变更捕获)实时同步,指的是在数据源发生变化时,实时地捕获这些变化,并将其应用到目标系统中,从而保持数据的同步性。 目前我们CDC同步方式兼容的源端数据库类型有:Mysql、Oracle、Sqlserver、Postgresql、Mongodb、Kafka、Evenstore等。
六)数据填报
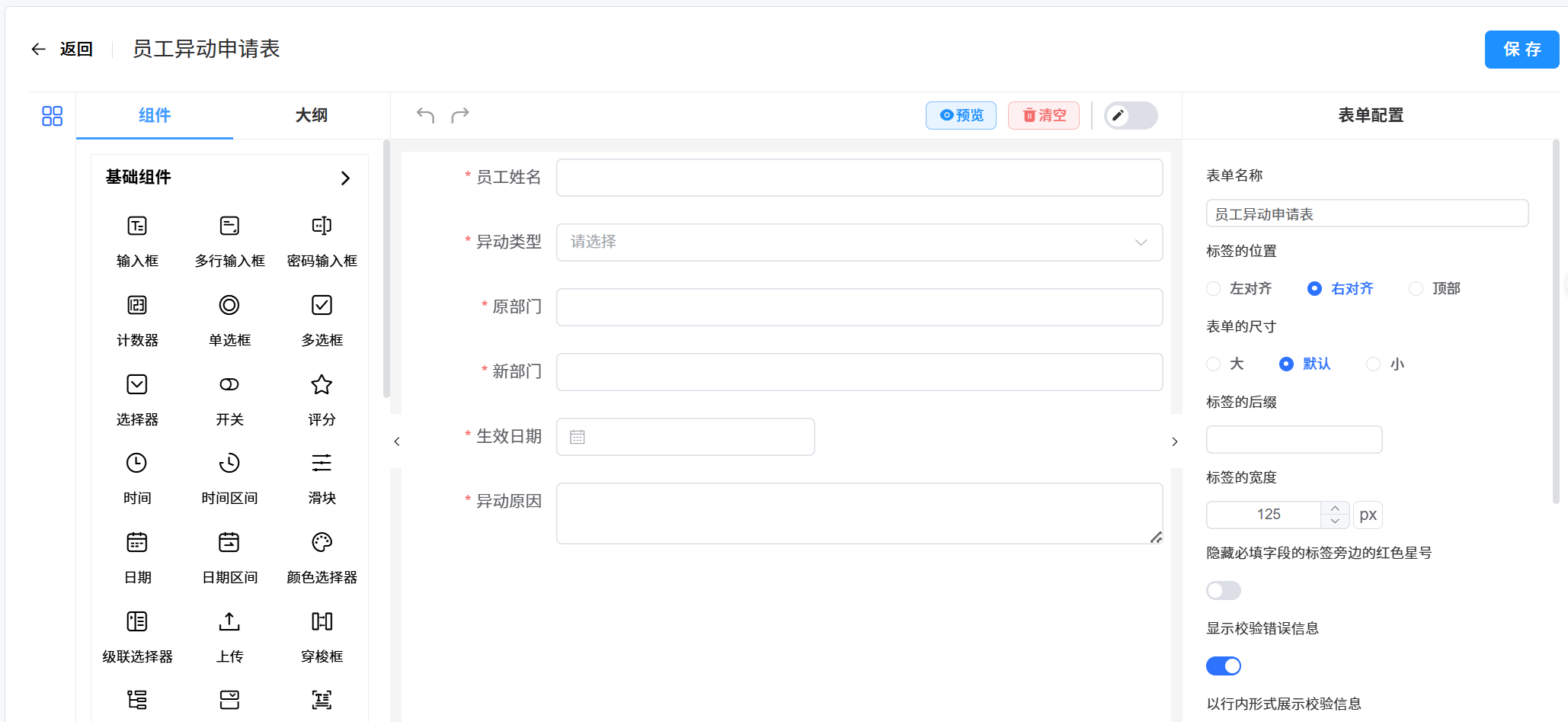
通过数十种丰富的表单设计组件和灵活的布局方式,满足各种复杂业务场景下的表单设计和数据填报需求,同时,系统还支持表单数据的实时存储、查询和分析功能,为业务决策和流程优化提供有力支持。通过拖拽配置数据填报模板,并且由管理人员指定哪些用户进行数据填报。支持数据导入、数据导出以及人员任务派发。
基础组件:系列基础组件、如输入框、多行输入框、密码输入框、计数器、单选框、多选框、选择器、开关、评分、时间、时间区间、滑块、日期、日期区间、颜色选择器、级联选择器、上传、穿梭框、树形控件、树形选择、富文本框、手写签名。
子表单组件:子表单、分组、表格表单。
辅助组件:提示、按钮、文字、标题、HTML、分割线、标签、图片。
布局组件:栅格组件、表格布局、标签页、间距、卡片、折叠面板。
手机端请关注公众号:数据集成服务
加入讨论群:
