
1. 背景与问题
随着政企数据规模持续扩大,数据安全问题日益凸显。尽管许多大数据中心已经建立了红区、黄区、绿区的安全架构体系,并通过行政指令、保密协议等手段约束外包与驻场人员,但数据泄露事件仍频频发生,数据黑市交易与个人隐私外泄屡见不鲜。
根本原因在于:传统安全架构偏重制度约束而非技术隔离,使得外包开发人员、运维人员等仍有机会接触到真实数据。
我们提出的解决方案,旨在通过项目空间(沙盒)机制、样本数据脱敏引擎、分类分级体系与API动态脱敏策略,从架构层面彻底切断非授权人员与真实数据的接触路径,实现“零数据接触式开发” 与“全流程可控脱敏”。
2. 数据中台防泄密总体流程
1)总体思路
通过“前置机集群数据加密 + 数据归集中心继承策略 + 数据质检样本 + 项目开发双沙盒空间 + API制作样本”五个环节构建数据全生命周期安全体系。
其核心理念是:数据可以流动,权限不能流失;模型可以迁移,数据永不裸露。
下图展示了完整的防泄密流程架构:
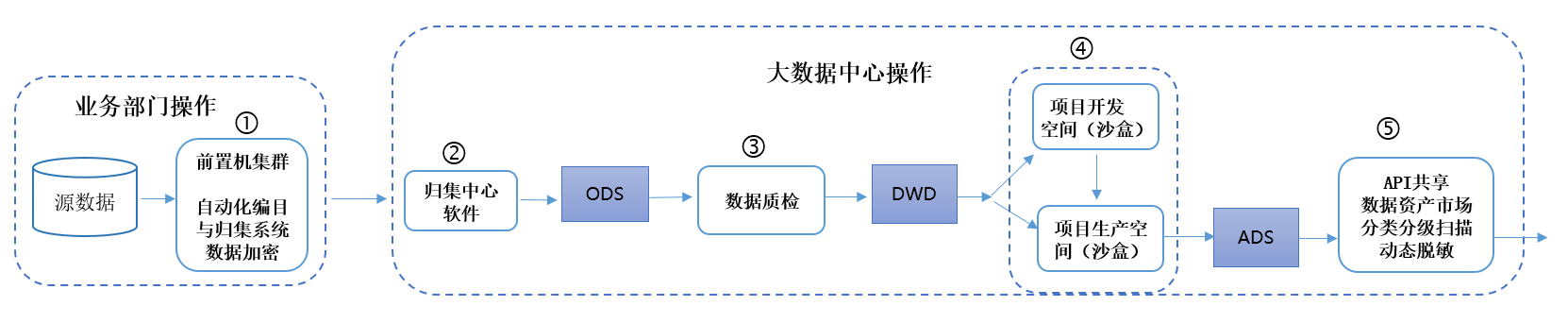
2)主要流程解读
① 前置机集群与数据加密归集
• 归集中心继承了前置机数据归集策略,自动将数据归集到ODS层;
• 数据在传输与归集过程中即被加密;
• 归集中心继承前置机策略,自动完成加密数据的汇聚与解密;
• 运维人员无法接触真实数据,系统全程自动处理。
② 归集中心软件入仓(ODS层)
• 数据自动进入ODS层;
• 归集中心运维与开发人员仅能查看任务状态与元数据信息;
• 所有实际数据的导入、转换均由系统自动执行。
③ 数据质检与脱敏样本生成
•在数据入仓前通过数据质量管理子系统的配置策略执行字段校验与规则检测;
•质检人员看到的仅是样本引擎自动生成的100条脱敏样例数据;
•样例数据遵循字段规则(如身份证仍为18位),但内容已失真。
④ 双沙盒开发机制(项目空间)
•项目组拥有两个完全隔离的空间:
√ 开发空间(沙盒):用于模型开发,数据为样本或Mock数据;
√ 生产空间(沙盒):运行真实数据,但开发者无查看权限;
•开发人员仅能将模型从开发空间同步到生产空间;
•生产数据仅由系统调度执行,结果可视化但无原始内容。
⑤ API共享与动态脱敏
•API配置生成过程中,开发人员只能通过界面看到样本数据;
•用户通过数据资产市场申请API共享时,系统将请求引导到API网关上;
•在API请求处理过程中,系统会根据申请用户的权限和分类分级策略进行动态脱敏处理,确保仅授权人员可以访问敏感数据;
•分类分级与用户等级绑定,通过设置权限等级来控制不同层次的数据访问,自动应用不同的脱敏策略;
•动态脱敏策略:
√自动检测输出字段中的敏感数据,确保敏感信息不会未经脱敏而外泄;
√根据用户角色、数据分级策略应用脱敏规则。例如,身份证号码只保留前6位和后4位,其他部分进行数字转换脱敏;
√支持脱敏规则模板化,常见脱敏规则如身份证号、手机号码、银行卡号等可以模板化配置;
√全链路记录脱敏动作与调用日志,确保所有操作都可追踪和审计,满足合规要求(如GDPR、数据安全法等)。
3. 样本引擎的作用
1)样本引擎概述
在数据防泄密的架构中,样本引擎扮演着至关重要的角色。样本引擎的核心功能是通过算法将真实数据转换为符合规则的脱敏样例数据,并确保数据的结构和属性在转换后保持一致,使得数据开发人员和运维人员在操作过程中无法接触到真实敏感数据。
样本引擎算法:通过对敏感数据(如身份证号码、手机号等)进行格式保持转换,将真实数据替换为符合原始格式的虚假数据,并确保转换后的数据具备足够的真实性与关联性,以支持开发和测试工作。
2)样本引擎处理规则 样本引擎不仅要保证数据的格式与属性完整性,还需遵循以下原则:
•数据的规则一致性:转换后的数据保留原有数据的校验规则,如身份证号码依然要符合校验位的规则,但不代表真实身份证号码。
•属性保留:例如将身份证号码转换后,地域信息、性别等属性要保留,与原数据一致。例如,若原数据身份证号码显示的是“上海”,则转换后的样本数据应仍然属于上海的用户。
•样例数据的一致性:对于表与表之间的关联数据,样本引擎确保同一身份证号码在不同表格中的转换结果一致,保证数据关联性不丢失。例如,表A和表B中有相同的身份证号码,经过样本引擎处理后,这个身份证号码的转换结果应该一致。
3)文本数据的转换 对于没有规则数据或文本数据(如地址、姓名等),样本引擎需要遵循以下转换规则(可以持续探讨):
•地址转换:以地址为例,如“上海市徐汇区虹梅路2007号6号楼202室”。样本引擎应智能转换地址中的数字部分,例如将地址中的“2007号6号楼202室”转换为“6111号8号楼616室”,并且转换后的数据依然具有合理性,确保驻场人员可以理解其含义。
•文本和规则数据转换:对于规则数据(如电话、邮箱),样本引擎应根据格式规则进行转换;对于无规则文本(如地址、姓名),引擎应进行合理的结构替换,确保数据逻辑可识别。例如,如果地址中包含数字,样本引擎将智能替换数字,但保持地址结构的完整性。
通过这种方式,样本引擎不仅保证了数据的脱敏处理,也确保了驻场开发人员和运维人员在数据开发与测试过程中能够理解数据的含义,从而不影响实际工作。
| 字段类型 | 脱敏策略 | 示例(真实→仿真) | 技术实现 | 关联性保障方法 |
|---|---|---|---|---|
| 工资 | 数值区间化(±15%随机波动) | 25000 → 21250-28750区间 | Python numpy随机波动算法 | 职位等级与工资区间强绑定(P7级对应固定区间) |
| 社保卡号 | 前6位地区码 + 哈希中间段(SHA-256) + 末4位 | 110123456789012 → 110123_9a8b7c_9012 | 数据库SUBSTR+哈希函数 | 地区码与身份证、电话区号一致 |
| 基因健康 | 基因位点AES加密,保留显性表型标签 | rs12345 → ENC(AES,rs12345) | PyCryptodome加密库 | 基因ID与医疗记录假名ID同步映射 |
| 组织级别数据 | 树形编码(总部A1→分部B2→科室C3) | 集团总部 → A1 | 组织架构图遍历算法 | 编码与部门、项目数据联动 |
| 组织部门 | 职能编码+随机后缀(TECH_01a) | 技术研发部 → TECH_01b | 数据库字典表映射 | 与员工职级、项目代码关联 |
| 身份证号码 | 前6位地区码 + 出生年 + 随机序列(17位是性别) + 校验码 | 320682199001011234 → 320682199001019871 | 正则表达式+校验码重算算法,按GB 11643-1999标准计算末位校验码 | 地区码与社保卡号、户籍地逻辑一致 |
| 个人生物识别信息 | 特征向量添加差分隐私噪声(ε=0.5) | 虹膜特征 → 向量+拉普拉斯噪声 | TensorFlow Privacy库 | 生物ID与用户假名ID单向绑定 |
| 银行账户 | BIN前4位 + 随机中间8位 + 末4位 | 6225881234567890 → 6225887295834162 | 随机数生成器(RNG),符合银联卡号纯数字规则(GB/T 15694.1-2019),末位2通过Luhn算法计算得出 | 账户类型与交易记录元数据关联 |
| 通信记录和内容 | 内容加密(AES-256),元数据泛化 | "转账给张三" → "通话类型: 金融操作" | OpenSSL加密 | 主叫/被叫号码脱敏后保留映射关系 |
| 财产金额 | 量级分段(10万级/100万级) | 1,234,567 → 100万级 | Pandas cut函数 | 财产量级与职业、征信分区间匹配 |
| 征信信息 | 信用分随机波动(±50分) | 689 → 650-700区间 | SQL窗口函数RAND() | 与职业稳定性、还款记录联动 |
| 行踪轨迹 | 坐标聚合至500米网格中心点 | 116.4075,39.9042 → 网格G-0238 | PostGIS ST_SnapToGrid | 同一用户轨迹点网格编码一致 |
| 健康生理信息 | 数值归一化到标准范围(如血压→110-130/70-90) | 120/80 → 标准范围 | 医学参考值区间替换 | 与疾病风险标签、用药记录关联 |
| 交易记录 | 时间戳按小时对齐,金额量级化 | 2023-08-20 14:35 → 2023-08-20 14:00 | 时间戳TRUNCATE函数 | 交易账户与用户假名ID双向映射 |
| 电话号码 | 前3位运营商 + 归属地中间4位 + 末4位 | 13812345678 → 13812349876 | Python random.randint | 运营商号段与归属地行政编码一致 |
| 性取向 | 泛化为分类标签(A/B/C) | 同性恋 → B类 | 标签编码(LabelEncoder) | 不与任何其他字段显式关联 |
| 婚史 | 状态编码(1=未婚, 2=已婚, 3=离异) | 离异 → 3 | 数据库ENUM类型 | 与家庭成员数量逻辑自洽 |
| 宗教信仰 | 替换为群体编号(G01-G99) | 佛教 → G05 | 预定义编号库 | 不存储具体宗教活动细节 |
| 未公开违法犯罪记录 | 全字段加密存储(国密SM4) | 盗窃案记录 → ENC(SM4,盗窃案记录) | 国密算法库(GMSSL) | 仅司法系统通过密钥解密 |
| 账号密码 | 替换为PBKDF2哈希值(迭代10万次) | Password123 → pbkdf2_sha256$... | Django密码哈希工具 | 哈希值与用户假名ID强绑定 |
| 姓名 | 姓氏保留+假名生成(同地区姓氏分布) | 张三 → 张天磊 | Python Faker区域定制库 | 姓氏分布与真实人口数据一致 |
| 精准定位坐标 | 高斯偏移(σ=100米)并保留相对位置 | 116.4075,39.9042 → 116.4083,39.9039 | Python numpy.random.normal | 同一地物偏移参数一致 |
| 家庭住址 | 替换街道名称与门牌号为虚构地址,保留城市与行政区划34 | 北京市海淀区中关村大街27号 → 北京市海淀区星辰路58号 | 通过定制化正则表达式精准提取省、市、区字段,对接行政区划代码库,预定义虚构路名库。 | 依据《个人信息保护法》和《地名管理条例》,定义敏感字段(街道、门牌号)为高隐私级别,需强制脱敏。省级/直辖市100%保留,地级市/区100%保留(含区级单位),街道/路名替换为虚构路名,门牌号替换为随机合规编号 |
以上只是样本引擎的示例,我们将不断改进,欢迎提出批评指导意见!
样本引擎可能会用到数据替换(Substitution)、数据扰动(Perturbation)、数据分段(Data Binning)、哈希(Hashing)、泛化(Generalization)、随机化(Randomization)、差分隐私(Differential Privacy)、加密(Encryption)、FPE(格式保留加密)等多种技术的组合。
4. 我们为什么没有提隐私计算?
常规情况下,我们要处理的数据包含了敏感数据,但不一定是高度涉密数据。而隐私计算对多方要求非常高,落地比较困难。当然,我们不是说要抛弃隐私计算,在非高度涉密的场景,为了达到防止数据泄露,又不影响计算性能,采用“样本引擎”是比较有效的手段,比“裸奔”要高出很多的安全保障。如下我们学习一下隐私计算技术。
1) 联邦学习(Federated Learning)
联邦学习是一种分布式机器学习方法,数据保持在本地设备上进行训练,避免了数据集中存储,从而有效保护了数据隐私。
(1)实现过程:
数据准备:各个业务单位(源数据单位)在各自的系统中准备相关的业务数据。数据必须符合联邦学习要求,即不同数据源之间的字段和数据类型需要统一或经过预处理。
模型设计与训练:大数据中心的技术人员负责在大数据平台中设计联邦学习模型。这一步通常会使用 TensorFlow 或 PyTorch 等框架,并在平台上创建训练任务,设置模型参数。
模型协同训练:在联邦学习的框架下,各个源数据业务单位的数据不会共享,而是在本地训练模型,并将训练后的参数(如权重、梯度等)上传到中心服务器。一体化大数据平台通过中心服务器将来自各个单位的模型进行聚合,并生成一个全局模型。
模型评估与优化:大数据中心负责评估联邦学习模型的效果,必要时调整模型算法,进行优化,确保最终模型的性能达到要求。
(2)配合要求:
大数据中心的人员:负责搭建 基础设施,配置联邦学习算法框架,设计并训练模型,进行模型评估和优化。
源数据业务单位的人员:提供业务数据,进行本地数据的预处理和模型训练,并上传训练参数,确保数据质量符合要求。
(3)联邦学习的挑战
联邦学习是一种在不集中数据的情况下进行机器学习的方式,其主要优势是保证数据隐私,但它也存在一定的困难,特别是字段定义和字段格式统一方面。确实,源数据由于各自的业务需求不同,字段定义和格式常常不一致,而联邦学习通常要求所有参与方的数据能够兼容并共享一些共同的特征空间。具体来说,联邦学习面临以下几方面的困难:
字段定义和字段格式的不统一:源数据难以统一字段和数据格式,特别是如果涉及到不同部门或单位之间的数据对接。即使通过标准化文档和工具提供帮助,实际操作中,字段差异仍然会影响数据的合并和处理。
虽然可以提供一种可行的方法是采用数据映射和字段标准化工具,自动化处理不同来源数据的统一格式,或者建立一套中间层的数据标准化接口,协同各方进行数据交换。但是,源数据不可能更改现在运行的系统,如果需要大量的数据标准化处理,谁有这个时间呢? 何况,源数据参与联邦学习的动机通常不足,特别是如果他们没有直接的利益或奖励来驱动这种合作。
2) 同态加密(Homomorphic Encryption)
同态加密是一种加密技术,允许在加密数据上直接进行计算而无需解密,这使得数据在计算过程中可以保持隐私性,适用于对敏感数据的计算场景。
(1)实现过程:
数据加密:源数据业务单位的数据通过同态加密技术加密后上传到大数据中心。加密时,数据会被转化为加密形式,在此过程中,一体化大数据平台要提供加密算法的支持,通常使用 RSA 或 AES 等加密算法。
加密计算:在大数据中心,通过同态加密框架进行计算。由于加密数据不能直接读取,平台会使用同态加密的计算方法,确保在计算时数据的隐私性得到保护。
结果解密:计算完成后,结果可以通过授权人员解密得到,通常会由业务单位的人员根据权限进行解密。解密后的结果可以用于后续的业务分析或决策支持。
(2)配合要求:
大数据中心的人员:负责同态加密的技术实现,部署加密计算框架,确保加密和计算过程中的安全性。同时,管理解密过程和权限控制。
源数据业务单位的人员:负责数据的提供,确保数据在上传前进行加密,同时根据需要为解密提供权限。
(3)同态加密的困境
同态加密的确为数据隐私保护提供了重要的技术保障,但它也带来了很大的挑战,尤其是在实际开发和数据分析的场景中。
数据不可见性:开发人员和分析人员通常无法直接看到加密后的数据内容,这给开发和分析工作带来了很大的不便。开发人员无法直观地进行数据开发,也无法直接基于数据进行分析,除非解密。
解密后暴露数据问题:你提到如果最终数据需要解密,那么加密实际上变得没有意义,因为运营人员仍然能看到原始数据。这是同态加密应用中的一个瓶颈。虽然可以采用分布式计算和数据权限管理策略,只有在必要的时刻、根据权限级别,才允许某些特定的人员进行解密或查看原始数据,但这会严重影响生产进度。
性能瓶颈:同态加密计算相比传统计算要慢很多,因此大规模数据的处理可能非常耗时,限制了其实时性和可扩展性。
3) 多方安全计算(MPC)
多方安全计算是一种允许多个数据持有方共同进行计算而不泄露各自数据的技术。每一方只能知道计算结果的一部分,无法得知其他方的数据。
(1)实现过程:
数据分割与加密:各源数据业务单位的数据首先会通过平台将数据切分,并通过 MPC 协议进行加密处理。每个数据持有方只知道自己的一部分信息,不会暴露其他方的数据。
协同计算:数据中心与各个业务单位共同参与计算过程。通过 MPC 协议,平台将不同方的数据进行加密并共同计算结果。此时,平台提供了一个中立的计算框架,能够确保各方数据隐私。
结果汇总:在计算结束后,通过 MPC 协议,平台可以汇总所有参与方的数据计算结果,并输出最终的分析结果,这些结果对各方都是可见的,但没有一方能直接访问其他方的原始数据。
(2)配合要求:
大数据中心的人员:负责部署 MPC 计算框架,确保数据加密、分割和计算过程的安全性。同时,协调不同业务单位的数据加密与计算过程,处理计算结果的汇总。
源数据业务单位的人员:参与数据的切分、加密和提供输入数据。同时,需要配合进行计算后的结果的验证和应用。
操作与配合总结
为了顺利完成上述技术的实施,大数据中心人员和源数据业务单位人员需要紧密配合,具体操作流程如下: 大数据中心人员需要负责平台的搭建与技术框架的设计,确保数据安全计算功能(如联邦学习、同态加密、MPC)的实现,并对数据流、模型训练、加密计算等各环节进行有效监控和优化。
源数据业务单位人员需要提供高质量的本地业务数据,并配合进行数据的加密、切分、上传等工作。业务单位还需遵循相关的数据隐私保护要求,确保加密、脱敏等措施到位。
双方的协作机制:双方应建立定期的沟通和协调机制,确保数据隐私保护工作顺利进行。通过定期的会议和报告检查进度,确保各环节按计划推进。
4) 预处理的内容可以包括:
(1) 字段名称的统一:
不同的数据源可能在字段命名上存在差异。例如,一个源数据业务单位可能使用 phone_number 来表示手机号,而另一个可能使用 mobile。在数据上传到大数据中心时,需要将这些字段进行统一,以便平台能够识别并处理这些数据。
例子:
源业务单位A:phone_number
源业务单位B:mobile
预处理:在上传数据之前,统一字段名为 phone_number,这样可以避免后续在合并数据时产生字段名称不一致的问题。
(2) 字段类型的统一:
不同的数据源中的字段类型也可能不同。例如,有些系统可能将日期存储为字符串("2025-01-01"),而另一些系统可能使用 Date 类型存储。为了能够在同一个计算任务中处理这些数据,必须将字段的数据类型统一。
(3) 字段值的标准化:字段值可能也需要统一格式。例如,地址字段在不同的数据源中可能包含不同的格式:有些可能包括省市区,另一些可能只包含城市,甚至可能有些字段包含不规范的拼写。为确保数据一致性和后续的分析,可能需要进行格式化和清洗。
例子:
源业务单位A:address 字段是 北京市朝阳区
源业务单位B:address 字段是 朝阳区 北京市
预处理:统一地址字段的顺序,或使用标准的地址解析库将地址拆分成省、市、区等字段,确保所有数据字段符合相同的格式。
(4) 数据的归一化与标准化:
一些字段值可能会有不同的范围或单位,尤其是对于数值型数据,例如收入、年龄等。为了使不同数据源的数据能够进行比较或合并,需要对这些数据进行归一化或标准化。
例子:
源业务单位A:salary 字段单位为人民币(10000 表示 10000 元)
源业务单位B:salary 字段单位为美元(10000 表示 10000 美元)
预处理:统一为同一货币单位(例如,统一为人民币),或者将不同单位的数据进行转换,确保数据的一致性。
(5) 缺失值和异常值处理:
不同的源业务单位在收集数据时,可能会遇到缺失值或异常值的情况。在上传数据之前,需要对这些数据进行清理,比如填充缺失值,或者对异常值进行处理(如删除或修正)。
例子:
源业务单位A:age 字段中有缺失值(NULL)
源业务单位B:age 字段中有不合理的年龄值(如 200)
预处理:可以选择用中位数填充缺失值,或删除包含缺失值的记录;对于异常的年龄值,可以设置一个合理的范围,并将超出范围的值进行修正或删除。
总结:
在数据源上传至大数据中心之前,源业务单位字段不仅需要与大数据中心的数据字段保持一致,还可能需要进行字段名称、数据类型、字段值格式的统一,并处理缺失值和异常值等。这一系列的预处理步骤是为了确保不同数据源之间能够兼容,并在后续的计算或分析中得到正确的结果。
5. 数据分类分级与动态脱敏体系
1)自动扫描与标签继承
• 分类分级系统在数据探查阶段自动扫描敏感字段;
• 在元数据管理模块中自动为字段打上分级与分类标签;
• 支持标签继承与扩散:
∘ 若 A 表 + B 表 → C 表;
∘ 且 A 表包含“身份证号”敏感字段;
∘ 则 C 表继承相同敏感标签。
2)人工干预与规则扩展
• 对于规则无法识别的字段(如“工资”),可人工标记;
• 支持根据行业规范(如GB/T 35273、数据安全法)配置安全等级。
3)动态脱敏策略
系统依据用户账户等级动态匹配脱敏方式如下,可以根据行业分类分级规范和用户等级定义方式在线配置:
| 用户等级 | 可访问数据级别 | 脱敏策略示例 |
|---|---|---|
| 三级(管理员) | 全量数据 S3分级 | 全字段脱敏或遮蔽 |
| 二级(内部审核) | 中等敏感数据 S2分级 | 局部脱敏(保留结构) |
| 一级(普通用户) | 低敏数据 S1分级 | 不脱敏 |
6.关键安全机制
| 安全机制 | 说明 |
|---|---|
| 权限最小化 | 所有开发者仅能访问必要资源,权限按职责分配 |
| 全流程脱敏 | 从源采集、质检、开发到共享均使用脱敏或伪造数据 |
| 双沙盒隔离 | 开发空间与生产空间完全隔离,数据与模型逻辑分离 |
| 全链路审计 | 记录所有操作日志与脱敏动作 |
| 策略模板化 | 常见脱敏规则可模板化重用 |
| 自动检测 | API配置阶段自动识别敏感字段 |
7. 防泄露成效
1)全员“零数据接触”
• 从数据采集到共享的每个环节,除管理员外无人能看到真实数据;
• 实现了“软件架构替代人防”的安全闭环。
2)合规与可审计
• 符合《数据安全法》《个人信息保护法》等法律要求;
• 所有数据操作可追踪、可回溯、可审计。
3)降低外包风险
• 外包开发团队在沙盒内完成所有工作;
• 无需签署额外的高风险数据访问许可。
4)动态防御与可扩展
• 数据脱敏规则与分类分级策略可动态更新;
• 支持多租户、多项目并行开发。
8. 总结
数据安全不应仅依赖制度与意识,而应嵌入软件架构之中。
手机端请关注公众号:数据集成服务
加入讨论群:
