
数据质量谁来负责?看起来这个问题比较简单,很多大数据中心认为,数据质量当然是源头负责,也就是源业务部门应该保证数据质量。国家发改委/国家数据局关于数据流通安全治理的解读明确:“数据提供方按照‘谁主管、谁提供、谁负责’的原则”;“数据接收方按照‘谁经手、谁使用、谁管理、谁负责’的原则”。这两句分别界定了供数与用数两端的主体责任。既然数据归集到大数据中心了,大数据中心加工后要对外其他业务单位提供共享服务,那么大数据中心就不能简单地将质量问题全部归咎于源头部门。而是需要在大数据中心与数源端形成一个相互协作的质量提升机制。
大数据中心对源数据做质量检查,然后形成报告,要反馈给源端部门,然后将脏数据也要返还给源端部门,让源端部门有的放矢,进行修正。另外,对于可以自行清洗的数据,大数据中心可以做好清洗和治理工作,比如将乱字符去掉,比如将“姓名+身份证号”的一个字段拆成“姓名”、“身份证号”两个字段,等等。
要建立一个大数据中心与源部门之间的相互协同机制,确保数据质量得到有效提升,我们可以从以下几个方面着手,明确方法和步骤:
(1)明确责任与角色分工
• 明确数据质量管理的责任主体:
• 数据提供方(源端):负责提供符合基本质量要求的源数据,并在数据提供过程中确保数据的完整性、准确性和一致性。
• 大数据中心:负责源数据的清洗、加工、存储,并提供质量报告反馈给源部门,协助源部门进行问题数据的修正。
(2) 质量检测与评估体系的建立
大数据中心需要建立一套完善的数据质量检测体系,确保能够有效地识别和评估源数据中的问题。关键步骤如下:
• 数据质量标准:定义明确的数据质量标准,包括数据的完整性、准确性、一致性、时效性、规范性等。
• 质量评估工具与流程:使用自动化工具进行数据质量检查,并设置定期或实时的质量评估流程,帮助及时发现数据质量问题。
• 质量检查报告:大数据中心应定期生成数据质量报告,报告内容包括数据质量评分、问题项详细描述、数据缺失或不一致的具体情况等。
(3) 反馈与修正机制
数据质量问题需要及时反馈给源部门,以便他们根据反馈进行修正。具体步骤包括:
• 问题数据反馈:通过数据质量报告,将数据中存在的质量问题、脏数据明确反馈给源部门,确保反馈内容清晰且具体,易于理解和修正。
• 修正与跟踪:源部门根据反馈报告修正数据问题,并将修正后的数据返回大数据中心。大数据中心要对修正后的数据进行重新检查,确保问题得到解决。
• 持续跟踪与闭环管理:大数据中心应持续跟踪源部门数据的修正情况,确保数据质量问题得以有效处理,最终形成闭环管理。
(4)建立协同工作机制
需要通过定期的协作会议、沟通机制等方式,确保大数据中心和源部门之间的紧密合作,持续改进数据质量:
• 定期沟通与反馈会议:建立定期的跨部门会议机制,讨论数据质量问题及解决方案,交流数据质量管理的最新进展,确保大数据中心和源端之间保持良好的沟通。
• 质量改进计划:大数据中心和源部门共同制定数据质量改进计划,明确短期和长期目标,逐步提升数据质量。
• 共享质量工具与方法:大数据中心可以将部分数据质量检测工具或清洗规则共享给源部门,协助他们在数据生成阶段就能避免一些常见质量问题。
• 考核评估与申诉机制:大数据中心可以根据源部门提供数据的质量进行定期考核和评估,制定相关指标,如数据的准确性、完整性和一致性等。这些评估结果可以作为源部门数 据质量管理的反馈依据,帮助源部门改进数据质量。同时,源部门若对考核结果有异议,可以提出申诉,经过双方讨论和调整,达成共识。通过这种机制,可以激励源部门持续改进数据质量,并保持公平的沟通渠道。
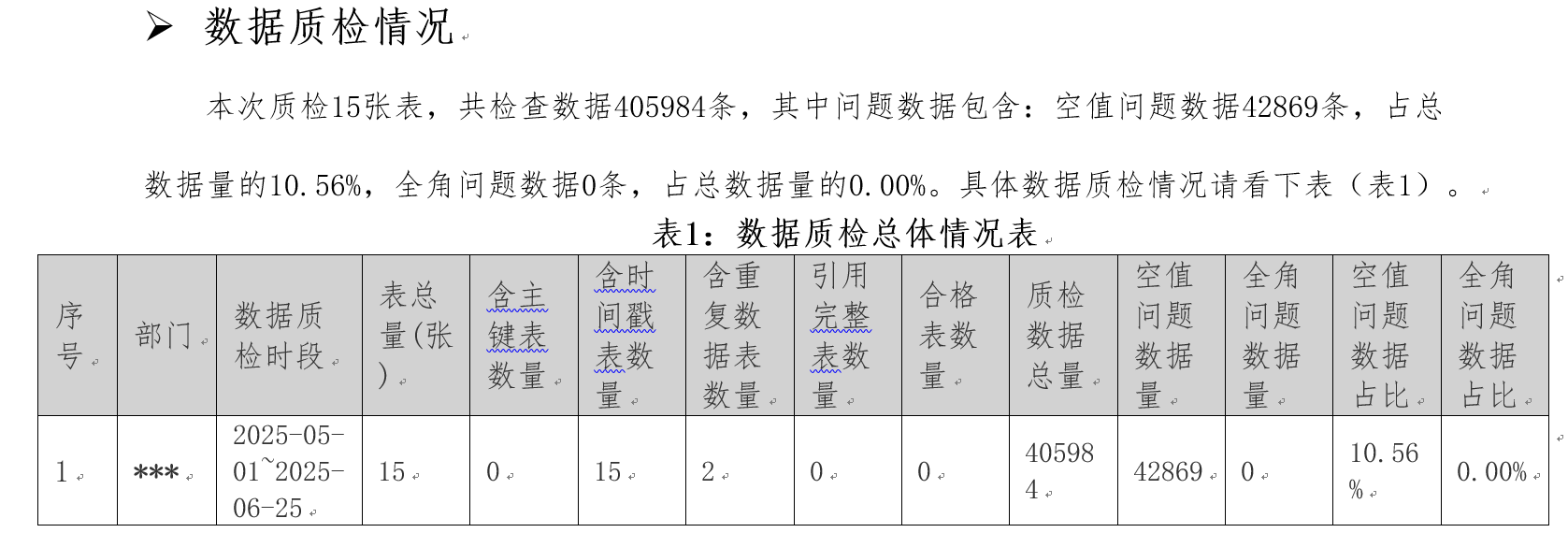
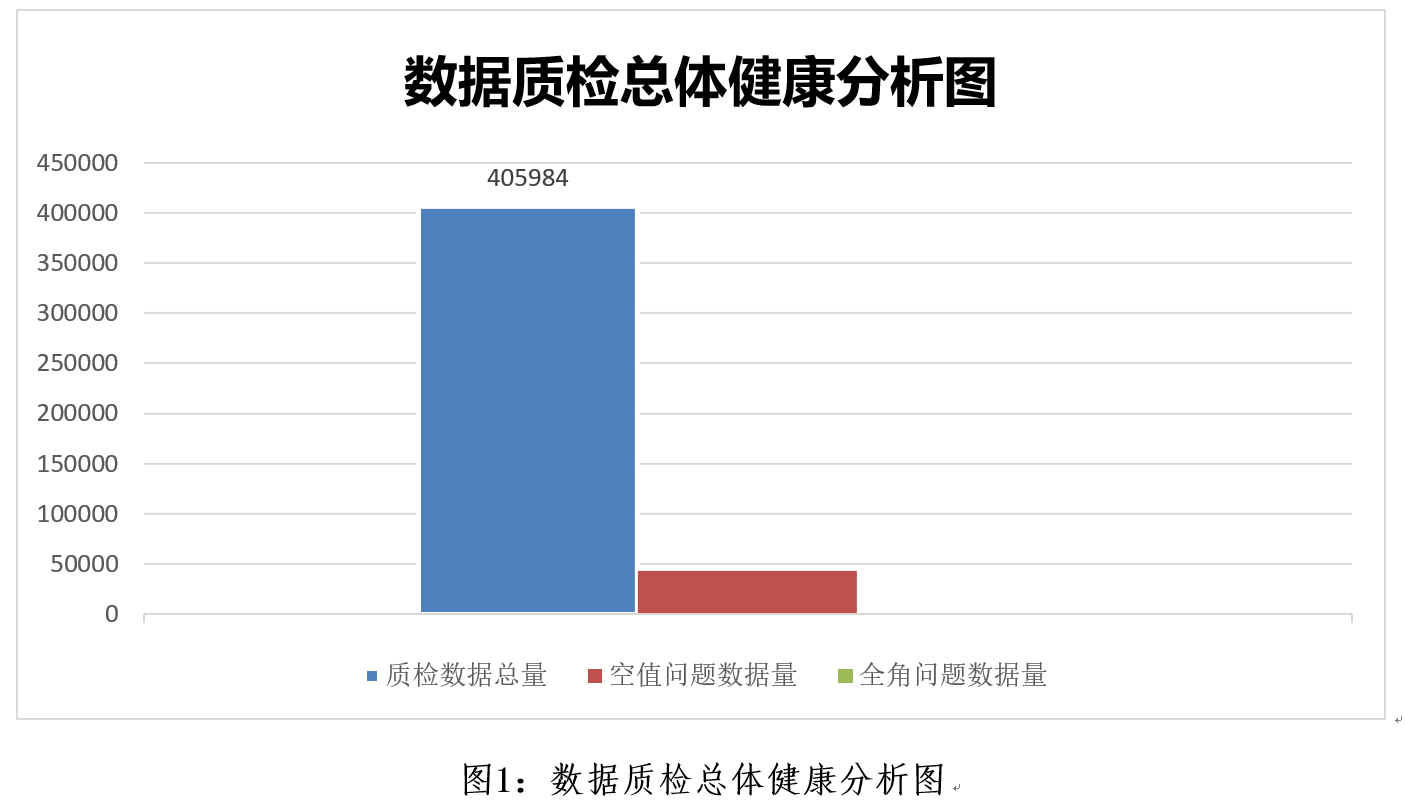
如下是来自多个项目中的数据质量考评方法摘录举例:

元数据完整性检测:检查表格的列名、数据类型、约束等信息是否都包含,是否有遗漏或损坏。
元数据准确性检测:检查一个字段的类型描述是否正确(例如,int 类型是否描述为整数类型),或者日期字段是否确实是日期格式。
规范库表的特点:
• 统一的命名规则:表名、字段名等遵循统一的命名规范,避免命名混乱或重复。
• 规范的数据类型:每个字段的数据类型符合预期的标准,比如日期类型字段使用 DATE,数值型字段使用 INT,避免数据类型不匹配。
• 合适的约束条件:表中的字段通常会有适当的约束条件(如主键、外键、唯一性约束、非空约束等),确保数据的完整性和一致性。
• 标准化的结构:表结构经过精心设计,符合数据库设计的标准化原则,避免冗余数据,并有良好的关联性。
• 清晰的文档化:规范库表通常会附有详细的元数据文档,描述每个字段的含义、数据类型和可能的取值范围等。
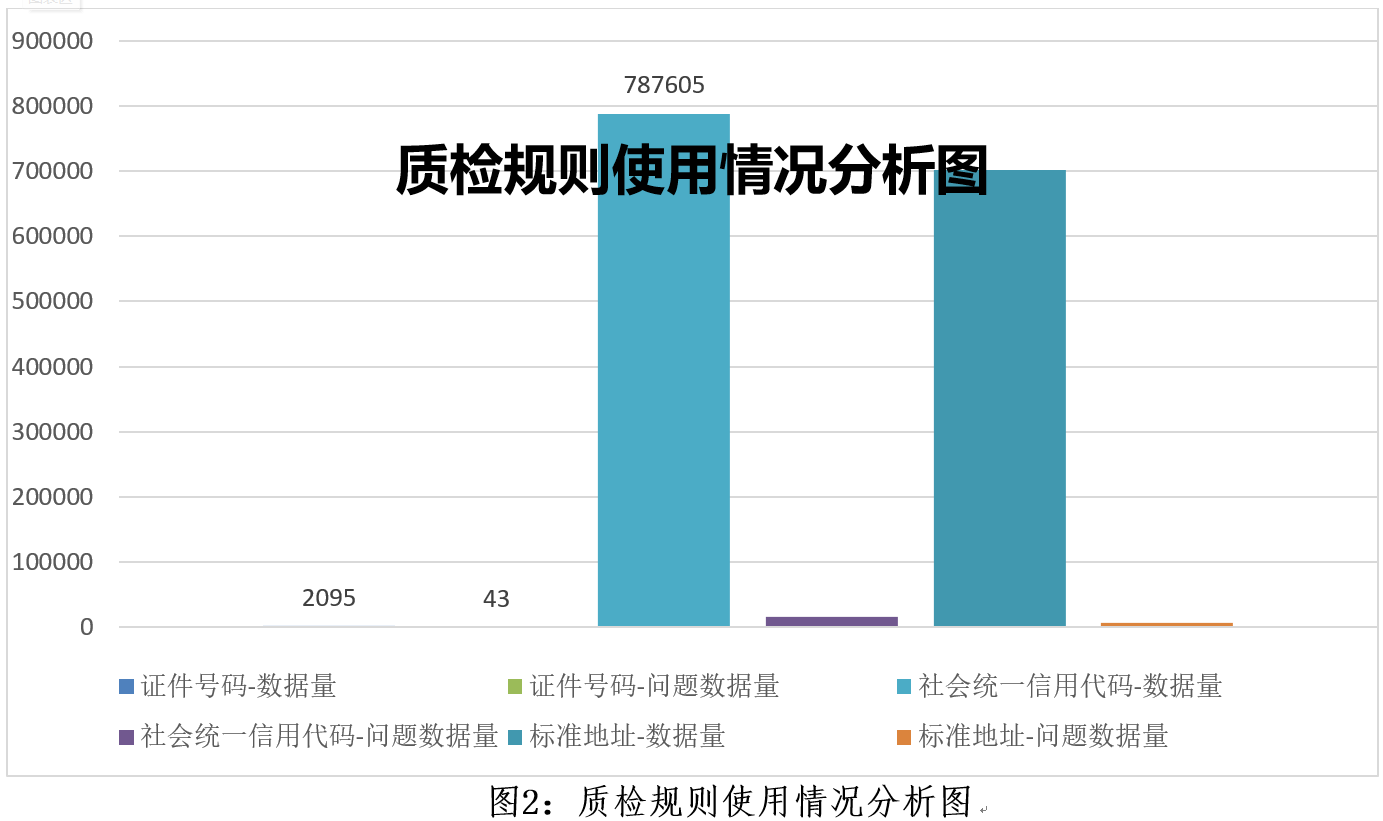
引用完整表检查:
• 外键约束的存在:检查表中的外键约束是否定义,是否每个外键都指向了正确的表和字段。
• 数据的参照完整性:检查所有外键字段是否真的引用了目标表中有效的记录。例如,如果某个订单表的 customer_id 外键引用了客户表的 id 字段,则检查每个订单记录的 customer_id 是否在客户表中有对应的客户。
• 更新和删除规则:检查外键的“更新”与“删除”规则(如级联更新、级联删除等)是否适当,以确保在修改或删除数据时不破坏引用的完整性。
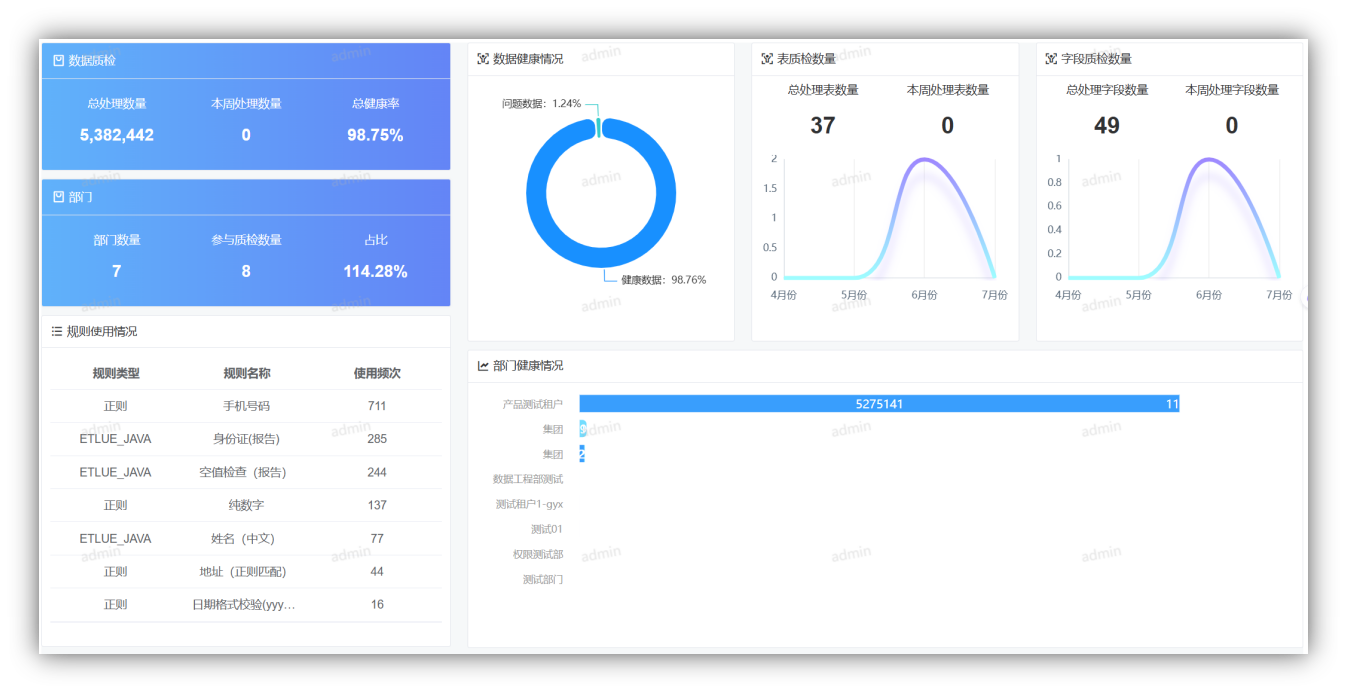
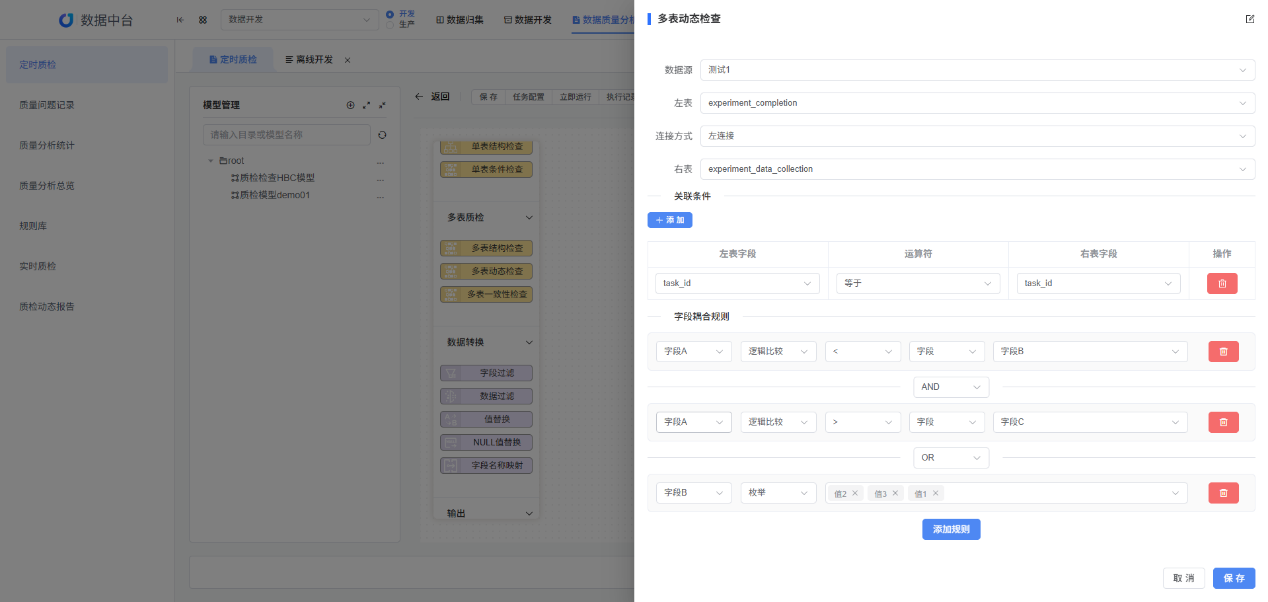
(5)自助清洗与治理能力建设
大数据中心需要提高自助清洗与治理能力,对于部分能够自行清洗的数据进行处理:
• 数据清洗工具:大数据中心需要开发或引入有效的清洗工具,自动识别脏数据并进行清理。例如,去掉无效字符、空值填充、标准化格式等。
• 数据治理规则库:建立数据治理规则库,涵盖各种常见的数据清洗与处理方法(如“姓名+身份证号”拆分为独立字段),并支持灵活应用。
(6)数据质量培训与知识共享
数据质量管理不仅仅是技术问题,更是组织文化的一部分。大数据中心和源端部门可以通过培训和知识共享,增强对数据质量的认知:
• 数据质量意识培训:定期为源部门和大数据中心的员工进行数据质量培训,提高员工对数据质量的敏感度。
• 经验共享与最佳实践:在跨部门会议中分享成功的案例和处理数据质量问题的最佳实践,帮助其他部门减少数据问题的发生。
(7)监控与自动化
数据质量管理应尽可能做到自动化和实时监控,确保数据质量问题能够及时发现并处理:
• 实时数据质量监控:通过监控系统对流入数据进行实时质量检测,及时发现问题并通知相关部门。
• 自动化清洗流程:在数据归集和处理流程中,自动触发清洗和修正规则,将清洗工作尽可能自动化,减少人工干预。
(8)数据质量的持续改进
数据质量管理是一个动态过程,不仅仅是发现问题,更要持续改进:
• 问题追踪与复盘:对于数据质量问题,进行根因分析和追踪,避免重复发生。
• 改进反馈循环:根据源部门反馈的数据修正效果,持续调整数据质量管理策略和方法,形成持续改进的循环。
总结
通过上述步骤,大数据中心与源部门能够建立起相互协作的数据质量提升机制。在这个过程中,关键是明确责任、建立质量评估体系、有效的反馈与修正机制、以及持续的沟通和协作。这种机制不仅有助于提升数据质量,还能实现各方资源的高效利用,促进数据管理的长效发展。
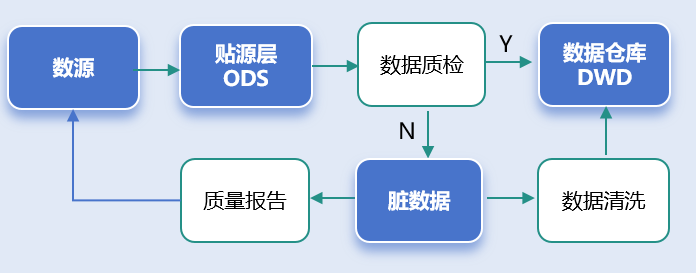
本文讲解视频请参见:
手机端请关注公众号:数据集成服务
加入讨论群:
